Autonomous ML Pipeline with Apache Airflow
In today’s data-driven world, companies are swimming in a continuous stream of information. This data is a goldmine, but extracting its value is a constant battle. Data teams spend hours on repetitive data cleaning tasks, and machine learning models quickly become stale as new data pours in.
What if you could build a system that automates this entire process? A system that not only ingests and cleans data but also trains new models, evaluates their performance, and intelligently decides which one to use in production?
it’s the power of workflow orchestration with Apache Airflow. In this post, we’ll explore how to build an end-to-end, automated data and ML pipeline that saves time, reduces errors, and creates a truly self-improving system.
First, let’s understand the core building blocks of Airflow.
What is Airflow? Understanding DAGs and Tasks
Before we dive into the case study, let’s demystify two key Airflow concepts: Tasks and DAGs.
- Task: A Task is a single step in your workflow. Think of it as one instruction in a recipe, like “Chop the onions” or “Preheat the oven.” In our data world, a task could be “Extract data from a database,” “Clean a data file,” or “Train a machine learning model.”
- DAG (Directed Acyclic Graph): A DAG is the complete recipe. It’s a collection of all your tasks, organized to show how they are related. The “Directed” part means the workflow has a clear direction—you chop onions before you sauté them. The “Acyclic” part means it doesn’t have loops; it has a clear start and finish. A DAG defines the what, when, and how of your entire workflow.
The Case Study: Predict customers who might unsubscribe
Now, let’s imagine a SaaS company. Their goal is to proactively identify customers who are likely to cancel their subscription.
The Data Challenge:
This Saas collects data from multiple sources continuously:
- User Activity Logs: From an internal database (e.g., MongoDB).
- Subscription Data: From a billing system (e.g., PostgreSQL).
- Support Tickets: From a third-party service API.
The Manual Nightmare:
Currently, their process is manual and painful. Every week, a data engineer runs scripts to pull, clean, and join this data. Then, a data scientist uses the resulting file to manually train and evaluate a new model, hoping it’s better than the last one. It’s slow, error-prone, and unsustainable.
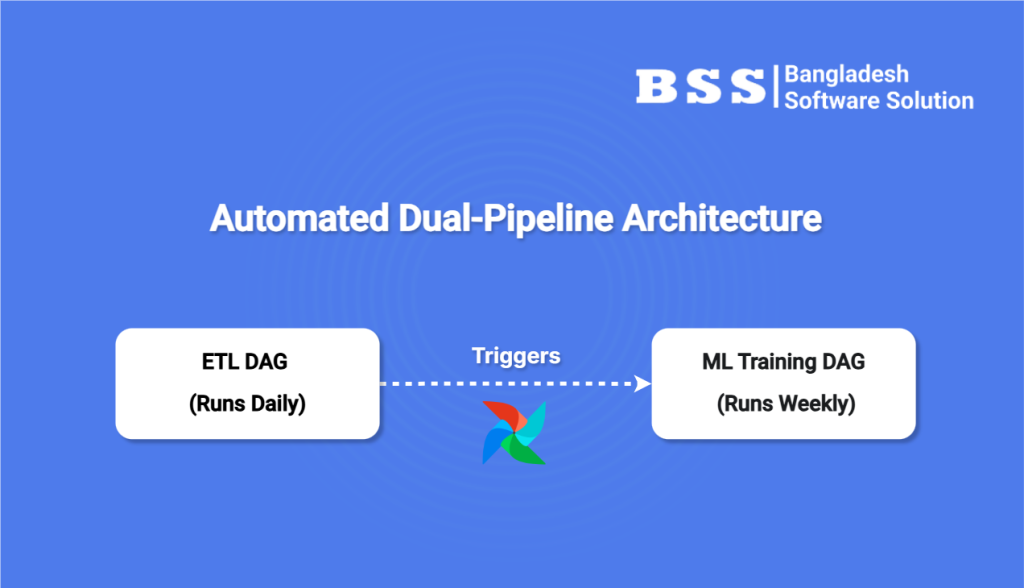
The Solution: An Airflow-Powered Dual-Pipeline
We can solve this by designing two interconnected DAGs to handle the ETL and ML workflows.
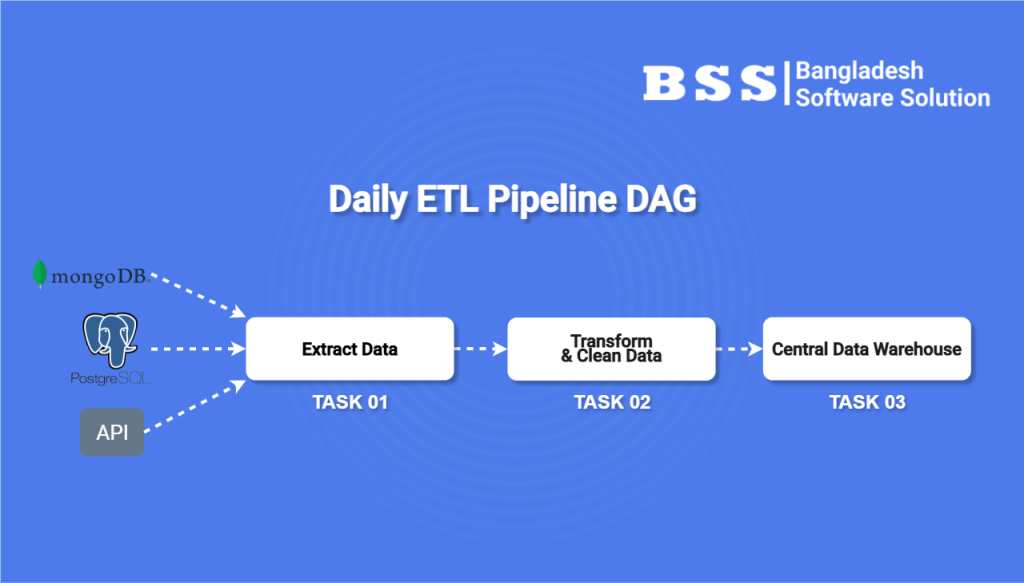
Part 1: The Automated ETL Pipeline
This DAG’s job is to run daily, collecting all new data, cleaning it, and storing it in a central data warehouse, making it ready for analysis.
- Task 1: Extract: The DAG starts with three parallel tasks. One for each data source (MongoDB, PostgreSQL, and the API). They run at the same time to fetch the latest data efficiently.
- Task 2: Transform: Once all three extraction tasks are complete, a single transformation task begins. It takes the raw data from all sources, cleans it (handling missing values, correcting formats), and joins it into one unified, analysis-ready table.
- Task 3: Load: The final task takes this clean, unified table and loads it into the company’s central data warehouse.
With this DAG scheduled to run daily, the database gets a consistently updated, clean dataset without anyone lifting a finger.
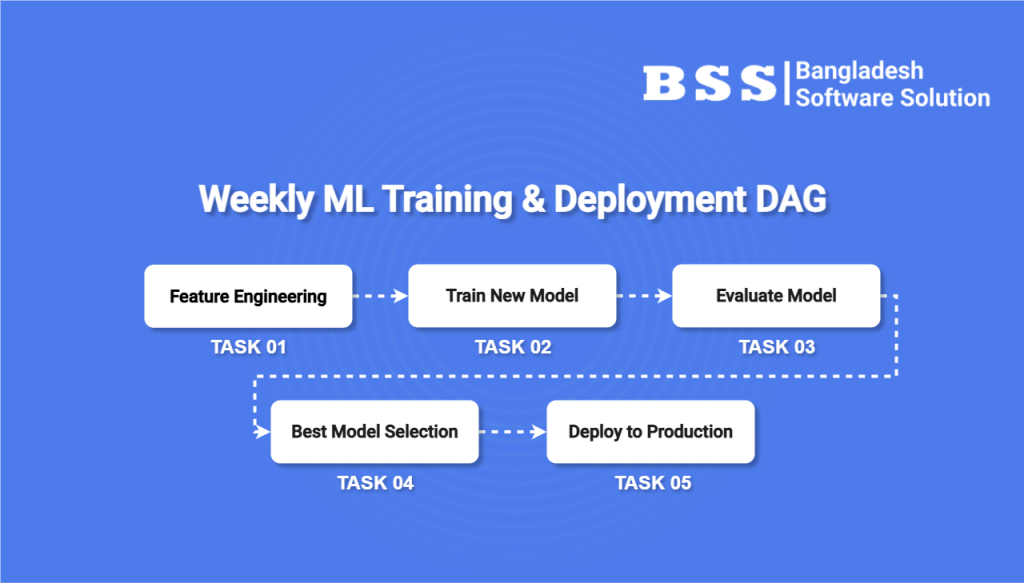
Part 2: The Self-Improving ML Pipeline
This is where the real magic happens. This DAG runs weekly, using the clean data prepared by our ETL pipeline to train a new model and intelligently decide if it’s good enough for production..
- Task 1: Feature Engineering: The pipeline starts by pulling the latest clean data from the warehouse. This task then creates model-ready features, such as “days since last login” or “average session duration.”
- Task 2: Train New Model: This task uses the new features to train a new churn prediction model. This new model is our “Challenger.”
- Task 3: Evaluate Model: The Challenger model is tested on a validation dataset. Its performance metrics (like accuracy or AUC score) are calculated and recorded.
- Task 4: The Champion vs. Challenger Showdown: This is the critical decision-making task. It compares the Challenger’s performance score against the score of the current model in production (the “Champion”). The Champion’s score is stored from its previous winning run.
- Task 5: Deploy or Reject (Conditional Path): Based on the comparison, the DAG chooses one of two paths:
- If the Challenger is better: A “Deploy” task runs. It promotes the Challenger model to become the new Champion, replacing the old one in production. It also updates the stored Champion score for the next run.
- If the Challenger is not better: The workflow proceeds down a “Reject” path, which simply ends the process. The current Champion remains in place, and nothing changes.
The Benefits of this Automated System
By building this with Airflow, any business gains a massive competitive edge:
- Automation & Efficiency: The data team is freed from repetitive tasks to focus on higher-value work, like creating better model architectures.
- Reliability & Monitoring: Airflow provides a user interface to monitor every run, get alerts on failures, and easily retry failed tasks.
- Scalability: As data grows, the system can be scaled to handle the load without redesigning the entire workflow.
- True MLOps: This system creates a closed loop where new data automatically leads to better models, ensuring the business is always using the most accurate predictions possible.
If your organization is stuck in a cycle of manual data processing, it’s time to stop running scripts and start orchestrating workflows. Apache Airflow provides a robust framework to build intelligent, self-sufficient pipelines that turn your data into a true, automated advantage.